Welcome to the Treehouse Community
Want to collaborate on code errors? Have bugs you need feedback on? Looking for an extra set of eyes on your latest project? Get support with fellow developers, designers, and programmers of all backgrounds and skill levels here with the Treehouse Community! While you're at it, check out some resources Treehouse students have shared here.
Looking to learn something new?
Treehouse offers a seven day free trial for new students. Get access to thousands of hours of content and join thousands of Treehouse students and alumni in the community today.
Start your free trial
Nils Sens
9,654 PointsNo launch button.
When I came i from speech-to-text, there was no launch button. Only "demo" and "getting started tutorial".
I feel the IBM services page was updated since this tut was made...
2 Answers
Ben Jakuben
Treehouse TeacherYou're correct - we recorded in October, and then IBM re-branded from Bluemix to IBM Cloud in November, including a light refresh on the page styling and branding.
Are you talking about the Launch Tool button shown here?
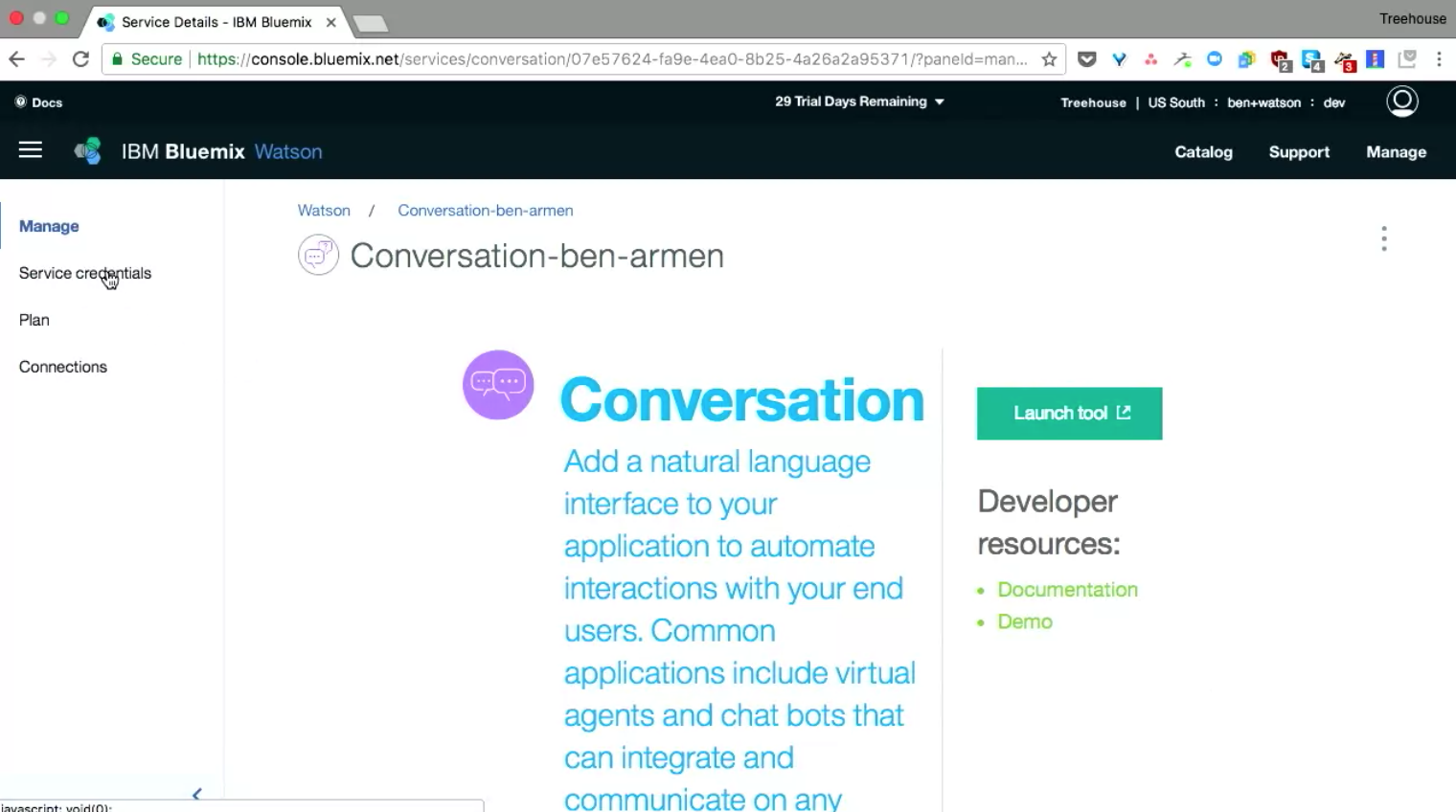
It works a little differently for Speech-to-Text. You don't need to configure a Workspace like we do for the Conversation Service. Once you create the service, you need to create credentials, then use those to make calls against the API from your client.
We are considering covering this in future material, but I'd recommend completing this course first with Conversation and Discovery services, and then coming back to the Speech-to-Text Getting Started guide to work through how to send audio data to this other service.
Hope this helps!
Nils Sens
9,654 PointsThank you for your response. Nevermind, I'm beginning to figure it out. I just made a successful API call from cURL, and now I'm thinking NODE.js would be the appropriate tool in order to make it work from within the app?
I'm going to go through a couple NODE.js tuts here now to see if that's the way to go. :)
What I basically need is instead of the sample FLAC audio file to access my microphone, and then to somehow "help" Watson by limiting the expected possible input in order to get better recog results for 4 and 2 (where their web demo failed sensationally, I guess because of possible ambiguity). I realized that whenever I say "Number two two" or "number four four" I got much better results. The context disambiguates, but how to force this onto Watson without the user having to say number in front of each number? Some more research ahead I guess....
Turning resulting numbers into button presses via jQuery will be trivial.